
Home » Alle berichten » Productiviteit » Dichtheidscurve: inzicht in verdeling en besluitvorming
Dichtheidscurve: inzicht in verdeling en besluitvorming
De dichtheidscurve is een krachtig instrument uit de statistiek dat verrassend waardevol kan zijn in uiteenlopende zakelijke contexten. Van klantsegmentatie tot risicoanalyse: met een juiste interpretatie van deze curve krijg je inzicht in hoe gegevens verdeeld zijn, waar concentraties liggen en waar uitzonderingen opduiken.
In tegenstelling tot bijvoorbeeld histogrammen, biedt de dichtheidscurve een vloeiender en gedetailleerder beeld van de onderliggende data. In dit artikel duiken we in wat een dichtheidscurve is, hoe je deze toepast, en wat je vooral niet moet vergeten als je er zakelijk voordeel uit wilt halen.
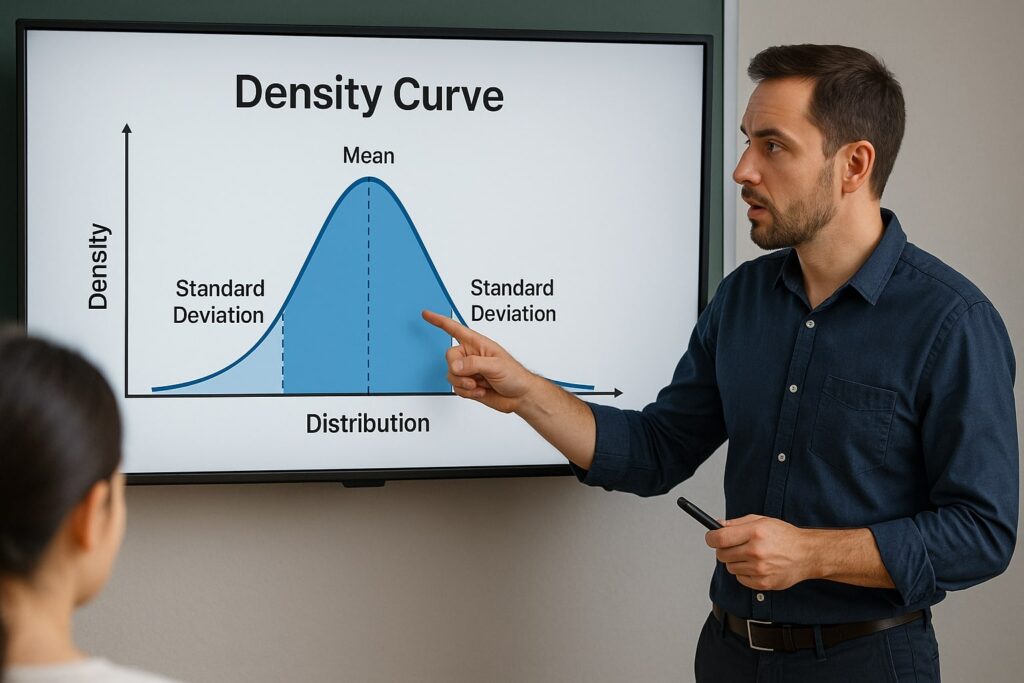
Wat is een dichtheidscurve precies?
Een dichtheidscurve is een grafiek die de waarschijnlijkheidsdichtheid van een continue variabele weergeeft. In plaats van data op te delen in kolommen zoals bij een histogram, laat een dichtheidscurve zien hoe waarschijnlijk het is dat een waarde voorkomt binnen een bepaald bereik.
Het totale oppervlak onder de curve is altijd gelijk aan 1. Dit betekent dat de curve je niet vertelt hoeveel waarnemingen er exact zijn, maar wel hoe die waarnemingen zich verdelen over het domein. Hoe hoger de curve op een bepaald punt, hoe groter de kans dat waarden zich in die regio bevinden.
Voor bedrijven betekent dit concreet dat je bijvoorbeeld kunt bepalen binnen welk bereik de meeste klantuitgaven vallen, hoe prijzen van producten zich gedragen of in welke mate levertijden verschillen.
Lees ook deze artikelen


De voordelen van de dichtheidscurve boven traditionele grafieken
Veel beslissers gebruiken standaard grafieken zoals staafdiagrammen of spreidingsplots. Toch biedt de dichtheidscurve voordelen die vaak onderbelicht blijven:
Vloeiend beeld van distributie: Geen grillige staven, maar een continu beeld van waar concentraties en uitschieters zich bevinden.
Makkelijker om meerdere verdelingen te vergelijken: Bijvoorbeeld tussen klantgroepen of tijdsperioden.
Helpt bij detectie van multimodaliteit: Ontdek je meerdere pieken in de curve, dan heb je waarschijnlijk met verschillende subpopulaties te maken.
Vooral dat laatste is cruciaal: veel bedrijven gaan ervan uit dat hun data normaal verdeeld zijn, maar in werkelijkheid is er vaak sprake van segmentatie. De dichtheidscurve maakt dat zichtbaar.
Dichtheidscurve en strategische segmentatie
Een van de meest onderscheidende toepassingen van de dichtheidscurve is het ontdekken van verborgen patronen in klant- of gebruikersdata. Wanneer je een dichtheidscurve maakt van bijvoorbeeld aankoopbedragen per klant, kun je zien of er meerdere ‘pieken’ zijn.
Zo’n piek kan wijzen op een specifiek klantsegment. Misschien heb je een grote groep klanten die kleine aankopen doet, en een kleinere groep die structureel veel besteedt. Door deze groepen visueel te herkennen, kun je marketingcampagnes, prijsstrategieën en productaanbod veel beter afstemmen.
Voor wie AI of machine learning inzet binnen het bedrijf: de dichtheidscurve helpt ook bij het bepalen van de juiste features om modellen te trainen.
Maak dichtheidscurves van klantwaarde (bijvoorbeeld CLV) per marketingkanaal. Je ziet dan direct welk kanaal niet alleen meer klanten oplevert, maar ook welke kwalitatief betere klanten aantrekt.
Hoe maak je een dichtheidscurve: praktische aanpak
Om een dichtheidscurve te maken, gebruik je meestal een kernel density estimation (KDE). Deze methode “smeert” de waarnemingen uit met behulp van een wiskundige functie (de kernel) en berekent op basis daarvan de curve. De belangrijkste elementen om rekening mee te houden:
Bandbreedte: Dit bepaalt hoe glad de curve wordt. Te klein? Dan krijg je ruis. Te groot? Dan verlies je details.
Schaal en assen: Zorg ervoor dat de curve correct geïnterpreteerd kan worden — het is géén frequentie, maar een kansdichtheid.
Vergelijkbare eenheden: Bij meerdere curves op dezelfde grafiek moeten de gegevens identiek geschaald zijn.
Populaire tools zoals Python (met libraries als Seaborn of Matplotlib) en R maken het eenvoudig om een dichtheidscurve te genereren. Voor ondernemers zonder programmeerkennis kan software als Tableau of Power BI uitkomst bieden.
Dichtheidscurve in combinatie met KPI-analyse
Stel je monitort de levertijd van orders. Met een gemiddelde en standaarddeviatie krijg je een globaal beeld. Maar de dichtheidscurve laat zien of die gemiddelde waarde representatief is, of vertekend wordt door uitschieters. Misschien ontdek je dat er twee clusters zijn: snelle leveringen binnen 24 uur, en vertraagde leveringen boven de 72 uur.
Zonder die curve zou je misschien onterecht concluderen dat je ‘redelijk goed scoort’ met een gemiddelde van 48 uur, terwijl de klantbeleving in werkelijkheid polariseert.
Deze toepassing geldt ook voor conversieratio’s, medewerkerstevredenheidsscores of productieafwijkingen. Kortom: waar je ook meet, de dichtheidscurve kan het echte verhaal onthullen.
Lees ook deze artikelen
Misverstanden over de dichtheidscurve
Er zijn een aantal hardnekkige misvattingen over dichtheidscurves die de interpretatie belemmeren:
“De hoogte van de curve geeft het aantal waarnemingen aan”: Onjuist. De hoogte representeert de kansdichtheid, niet het absolute aantal.
“Een symmetrische curve betekent altijd een normale verdeling”: Fout. Ook andere verdelingen kunnen symmetrisch zijn, denk aan uniforme of tweemodale verdelingen.
“Als er meerdere pieken zijn, is er iets mis met de data”: Integendeel. Meerdere pieken wijzen vaak op interessante segmentatie.
Juist door deze misverstanden aan te pakken, kun je de dichtheidscurve op een professionelere manier inzetten in je data-analyse.
Dichtheidscurve als onderbouwing voor besluitvorming
Wanneer beslissingen genomen worden op basis van gemiddelden of gemiddelden met spreiding (zoals standaarddeviatie), mis je de nuance. De dichtheidscurve biedt die nuance. Je kunt zien hoe uitgesproken bepaalde waarden zijn, waar risico’s zich concentreren, en waar potentieel verborgen zit.
Gebruik dichtheidscurves om je testgroepen visueel te vergelijken vóór je A/B-testen draait. Zo voorkom je dat je twee groepen vergelijkt die intern al sterk verschillen, wat je resultaten zou vertekenen.
Een goed voorbeeld is prijsstelling. Stel je hebt een dataset van concurrerende prijzen. Door daar een dichtheidscurve op los te laten, kun je zien waar het prijspunt van de meeste spelers ligt — en waar er nog ruimte zit om te concurreren zonder direct in een prijsoorlog te belanden.
Ook bij personeelsanalyses is dit nuttig: de verdeling van prestaties, beoordelingsscores of werkdruk kan veel onthullen over teamdynamiek of managementeffectiviteit.
Het belang van samplegrootte en interpretatie
Een dichtheidscurve is slechts zo betrouwbaar als de data waarop deze gebaseerd is. Een veelvoorkomend probleem is dat ondernemers conclusies trekken op basis van een te kleine steekproef. Bij kleine datasets kan de curve vertekend zijn, of juist kunstmatig gladgemaakt worden door de bandbreedte.
Een praktische richtlijn: gebruik de dichtheidscurve alleen als je minimaal 50 datapunten hebt, en idealiter meer dan 200 als je subsegmenten wil vergelijken. Anders loop je het risico op overinterpretatie.
Daarnaast is het verstandig om de curve altijd te combineren met andere visuele hulpmiddelen, zoals boxplots of cumulatieve grafieken. Zo krijg je een vollediger beeld.

Frederiek van Leeuwen
Frederiek van Leeuwen is een vaste auteur voor ZakelijkPlus.nl en schrijft over de thema’s die ondernemers vandaag en morgen bezighouden. Met een focus op bedrijfsvoering, digitalisering, apps en juridische vraagstukken rondom ondernemerschap, biedt zij heldere inzichten en toepasbare adviezen. Dankzij haar scherpe blik op technologie, wet- en regelgeving én praktische bedrijfsrealiteit weet Frederiek complexe onderwerpen toegankelijk te maken voor ondernemers die vooruit willen.
Bekijk ook deze categorieën